(图文|信息 编辑|辛西 审核|李国亮)近日,我校陈洪教授领衔的人工智能与统计学习团队在CCF A级人工智能国际会议The 32nd International Joint Conference on Artificial Intelligence (IJCAI2023)发表题为“Generalization Bounds for Adversarial Metric Learning”的研究论文。该文章从人脸识别、信息检索等应用基础——度量学习出发,利用统计学习理论首次分析了成对样本的对抗学习算法的鲁棒性和泛化性,为相关应用提供了理论指导。
研究人员表示,目前基于成对样本的对抗学习算法研究取得了一系列的经验性成果,极大增强了应用于人脸识别、信息检索、身份重定位等领域的机器学习模型的鲁棒性,提高了模型预测性能。然而基于成对样本的对抗学习算法的泛化性质和内在机理的理论研究却十分匮乏,缺乏经验上有效性的理论保证。
对抗度量学习的理论分析主要存在两大难点:其一,对抗学习的非平滑性和不可微分性通常会导致计算分析的困难,而关于样本对的对抗损失的分析和转化进一步加剧了分析难度;其二,度量学习中样本对是非独立同分布的,这导致传统基于独立同分布假设的集中估计技术和工具不再适用。为克服上述困难,研究团队首先建立逼近于成对扰动下对抗损失类的假设函数类,再利用覆盖数工具来刻画假设函数空间的复杂度。基于函数类的覆盖数估计,建立了对抗度量学习在样本对扰动下的首个高概率泛化界,其收敛率为O(n^(-1/2) )。此外,通过利用与样本块相关的局部Rademacher复杂度,进一步获得平滑损失条件下快速收敛率O(n^(-1) )。上述理论结果揭示,通过输入的低维子空间投影和模型权重的正则化约束等能提高对抗度量学习算法的泛化性,并通过数据实验验证了该理论发现(如下图1和图2所示)。
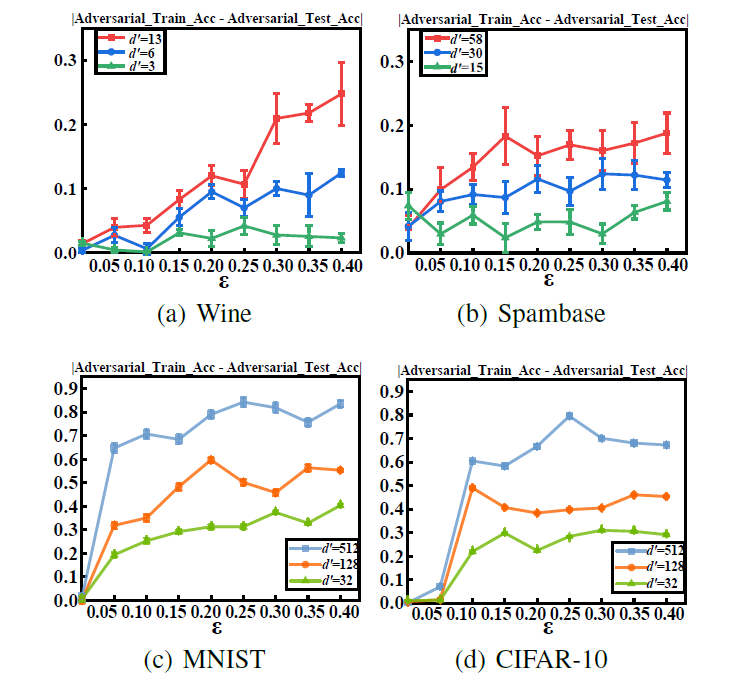
图1. 对抗度量学习算法在不同映射维度(d')下的经验泛化误差
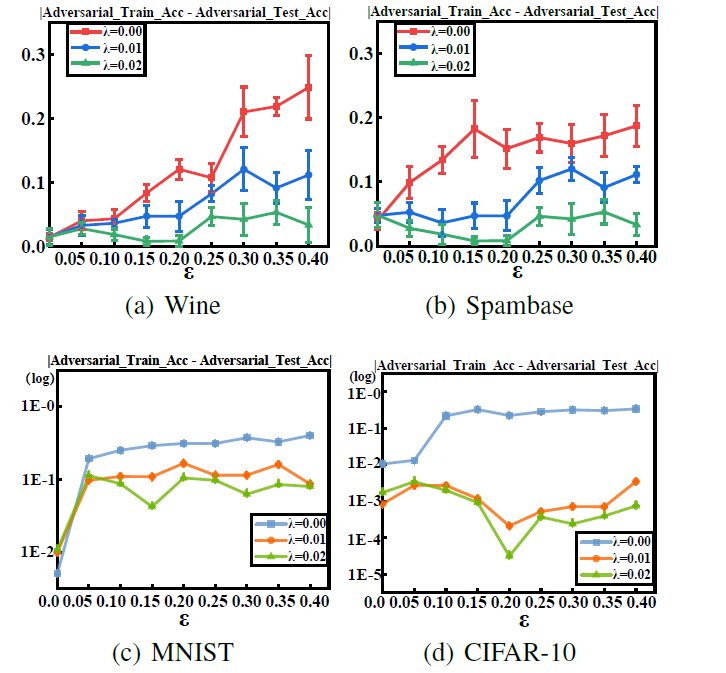
图2. 对抗度量学习算法在施加〖 L〗_1正则(λ≠0)和无L_1正则(λ=0)约束下的经验泛化误差
我校beat365体育亚洲版硕士生文雯为该论文第一作者,beat365体育亚洲版李函副教授为论文通讯作者,beat365体育亚洲版武玲娟副教授等参与了实验设计工作,理学院陈洪教授指导了研究选题及论文撰写工作。该项工作得到国家自然科学基金、中央高校基本科研业务经费资助。